
Medical Domain Identification in Patient prescription using NLP
Utilizes natural language processing to classify and extract key medical terms from unstructured data, by healthcare analysis
Abstract
This project addresses the intricate task of deciphering medical records and transcriptions to enhance patient segmentation efficiency. Leveraging a Kaggle dataset containing authentic medical writings, our approach involves a meticulous preprocessing pipeline. This includes robust data cleaning and lemmatization to streamline text, followed by TF- IDF vectorization for numerical representation. To manage the resulting extensive feature space, Principal Component Analysis (PCA) is employed. The core of our model utilizes a Random Forest classifier to train on the processed data, with a primary focus on accurately categorizing patients into specialized medical fields based on their transcriptions. The ultimate goal is to streamline patient management, offering benefits to both hospital staff and patients. To further extend the project's utility, we propose an enhancement that allows for the creation of custom categories or tags tailored to specific hospital or clinic needs. This customization feature promises to provide more granular insights into patient conditions and treatments. This project represents a significant advancement in the field, offering a practical solution for healthcare professionals to efficiently manage patient information. Future enhancements will build upon this foundation, continually refining and expanding the model's capabilities to meet evolving healthcare demands.
1.1 Introduction
Emergence in the 1990s:
Soft Computing, as a paradigm, emerged in the early 1990s in response to the need for computational approaches that could handle uncertainty, imprecision, and approximate reasoning. It was recognized that traditional computing models, reliant on binary logic and precise values, struggled to address the complexity inherent in real-world problems.
Foundational Components: The three foundational components of soft computing are fuzzy logic, genetic algorithms, and neural networks. Fuzzy logic, inspired by human decision-making processes, allows for the representation of uncertainty through linguistic terms. Genetic algorithms draw inspiration from natural selection and evolution, providing a stochastic optimization approach. Neural networks, inspired by the human brain, simulate learning and decision-making processes.Evolution and Applications: Soft computing has evolved over the years into a versatile toolset, finding applications in various fields such as control systems, optimization, pattern recognition, and data mining. Its ability to handle uncertainty and imprecision has made it particularly well- suited for addressing complex, real-world problems where precise solutions may be elusive.
History of Image Processing:
Early Developments (1960s): The history of image processing can be traced back to the 1960s when digital computers became available. Initial applications focused on enhancing the quality of satellite and medical images. Researchers began exploring ways to manipulate visual information for improved analysis and interpretation.
Shift to Computer Vision (1970s-1980s): In the subsequent decades, there was a notable shift towards computer vision, where image processing extended beyond basic enhancement to the interpretation of visual information. Advancements in hardware capabilities and algorithms allowed for more sophisticated analysis, including object recognition and scene understanding.
Modern Era and Machine Learning Integration: The modern era of image processing is characterized by the integration of machine learning and deep learning techniques. This integration has revolutionized the field, enabling automated feature extraction, object detection, and classification. Applications span diverse domains, from medical imaging to facial recognition and autonomous vehicles.
1.2 Working Principle
Image Analysis:During image analysis, quantitative information is extracted from the image data. This involves using algorithms and computational techniques to identify patterns, relationships, and trends within the image. Machine learning and artificial intelligence methods may be employed for complex analysis tasks.
Post-processing: Post-processing involves refining the results obtained from image analysis. This may include further filtering, merging segmented regions, or additional adjustments to enhance the interpretability of the results.
Overall, the working principle of image processing involves a systematic application of various techniques to transform raw digital images into meaningful information for analysis, interpretation, and decision-making in diverse fields such as medicine, astronomy, remote sensing, and computer vision.
1.3 List of Applications
1. Medical Imaging
2. Facial Recognition
3. Object Detection and Recognition
4. Satellite Image Processing
5. Document Analysis
6. Robotics
7. Augmented Reality (AR) and Virtual Reality (VR)
1.4 Challenges and Pitfalls
Image processing, while a powerful tool across various fields, confronts several challenges and pitfalls. One of the primary issues is the presence of noise and distortions in images, stemming from factors such as sensor imperfections or environmental conditions. Additionally, the computational complexity of image processing tasks can pose a hurdle, demanding substantial computing resources. The ambiguity and subjectivity in interpreting images add a layer of complexity, as defining objective criteria for processing becomes challenging. Limited information due to incomplete or low-resolution images can compromise the accuracy of processing algorithms, while variability in illumination and calibration issues may impact the reliability of results. Privacy concerns also arise, particularly in applications like facial recognition, raising questions about data security and potential misuse. Moreover, ethical considerations emerge, as biases in training datasets can result in discriminatory outcomes, prompting a need for careful evaluation and refinement in image processing applications.
Existing Techniques
2.1 Unstructured Text Analysis in Healthcare
Unstructured text, such as medical records and social media comments, provides a wealth of data for clinical research. Natural language processing (NLP) is increasingly vital in the data-driven field of medicine, offering opportunities to innovate healthcare delivery and ophthalmic treatment. Healthcare systems worldwide struggle to meet the 'quadruple aim' by improving population health, enhancing patient experiences, and reducing care costs. Factors like aging populations and rising healthcare expenses drive the need for innovative care models. The global pandemic has accelerated the demand for effective, quality care and highlighted workforce shortages and care access disparities. Patient-centered care necessitates assessing healthcare experiences across all care transitions, with NLP aiding in extracting insights from patient feedback. Leveraging NLP for unstructured text analysis can provide valuable insights to enhance healthcare delivery and patient outcomes. The support vector machine (SVM) ML model produced the highest accuracy in predicting themes and sentiment. The most frequent single words relating to transition and continuity with a negative sentiment were “discharge” in inpatients and Accident and Emergency, “appointment” in outpatients, and “home’ in maternity. Tri-grams identified from the negative sentiments such as ‘seeing different doctor’, ‘information aftercare lacking’, ‘improve discharge process’ and ‘timing discharge letter’ have highlighted some of the problems with care transitions. None of this information was available from the quantitative data. NLP can be used to identify themes and sentiment from patient experience survey comments relating to transitions of care in all four healthcare settings. With the help of a quality improvement framework, findings from our analysis may be used to guide patient-centred interventions to improve transitional care processes.
2.2 NLP Techniques in Healthcare Information Processing
Olaronke G. Iroju, Janet O. Olaleke: The healthcare system is a knowledge-driven industry which consists of vast and growing volumes of narrative information obtained from discharge summaries/reports, physicians case notes, pathologists as well as radiologists reports. This information is usually stored in unstructured and non-standardized formats in electronic healthcare systems which make it difficult for the systems to understand the information contents of the narrative information. Thus, the access to valuable and meaningful healthcare information for decision making is a challenge. Nevertheless, Natural Language Processing (NLP) techniques have been used to structure narrative information in healthcare. Thus, NLP techniques have the capability to capture unstructured healthcare information, analyze its grammatical structure, determine the meaning of the information and translate the information so that it can be easily understood by the electronic healthcare systems. Consequently, NLP techniques reduce cost as well as improve the quality of healthcare. It is therefore against this background that this paper reviews the NLP techniques used in healthcare, their applications as well as their limitations.
2.3 Sentiment Analysis in Health-related Discourse
Anastazia Zunic, Padraig Corcoran, Irena Spasic: Sentiment analysis (SA) is a subfield of natural language processing whose aim is to automatically classify the sentiment expressed in a free text. It has found practical applications across a wide range of societal contexts including marketing, economy, and politics. This review focuses specifically on applications related to health, which is defined as “a state of complete physical, mental, and social well-being and not merely the absence of disease or infirmity.” This study aimed to establish the state of the art in SA related to health and well-being by conducting a systematic review of the recent literature. To capture the perspective of those individuals whose health and well-being are affected, we focused specifically on spontaneously generated content and not necessarily that of health care professionals. Our methodology is based on the guidelines for performing systematic reviews. In January 2019, we used PubMed, a multifaceted interface, to perform a literature search against MEDLINE. We identified a total of 86 relevant studies and extracted data about the datasets analyzed, discourse topics, data creators, downstream applications, algorithms used, and their evaluation.
Figure 1. Connectivity of Project Workflow
III. PROPOSED METHOD
3.1 Objective
• Develop a robust NLP model for precise medical data categorization.• Implement effective data preprocessing and dimensionality reduction.
• To enhance patient segmentation and data management in healthcare.
3.2 Implementation of Modules
The IoT system mainly focuses on 3 different stages of implementation.The 3 modules are, namely
1) Data Collection and Preprocessing
2) Feature Extraction and Transformation
3) Model Building and Evaluation
3.3 Connectivity Diagram
Following Diagram depicts all the stages in a sequential Flow
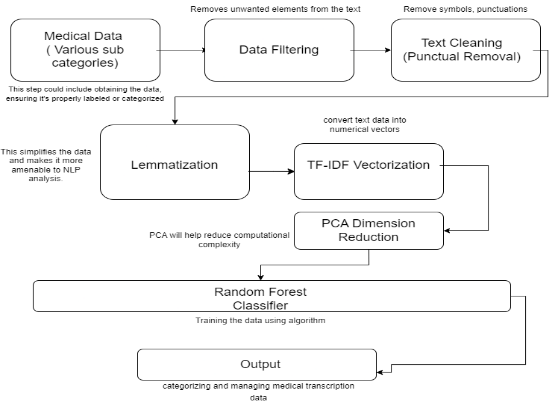
Figure 2. Connectivity of Project Workflow
3.4 Module DescriptionData Collection and Preprocessing
The initial phase involves the collection of medical transcription data spanning various sub-categories within the medical domain. This diverse dataset is then manually categorized into sub-categories to ensure a comprehensive representation. A critical criterion is set to include only those categories with a minimum of 50 data samples, ensuring an adequate dataset for robust model training.
Data Cleaning and Lemmatization:
To enhance the quality of the dataset, a meticulous cleaning procedure is implemented. This involves the removal of symbols, punctuation, and other unwanted elements from the transcriptions. Following this, lemmatization is applied to streamline the data further, reducing words to their root form. These preprocessing steps are fundamental to refining the raw data for subsequent analysis.
Feature Extraction and TransformationTF-IDF Vectorization:
This module delves into the implementation of TF-IDF vectorization, a crucial step in converting textual data into numerical vectors. The TF-IDF methodology is employed to evaluate the importance of words in context creating feature vectors that encapsulate the significance of each term within the dataset.Dimensionality Reduction (PCA):Addressing the computational complexity of the dataset, Principal Component Analysis (PCA) is introduced. PCA serves as a pivotal technique for reducing the dimensionality of the data, streamlining the feature space and enhancing computational efficiency for downstream analysis.
Model Building and EvaluationNLP Model Development:
The project advances to the development of a robust Natural Language Processing (NLP) model. An algorithm, such as the Random Forest Classifier, is chosen for its suitability in handling medical transcription data. The dataset is partitioned into training and testing sets, and the model is trained using the designated training data.
Model Evaluation and Reporting:
This crucial phase involves evaluating the performance of the NLP model. Relevant metrics, including accuracy, precision, recall, and F1 score, are employed to assess the model's effectiveness. Adjustments are made to the model and its parameters to optimize performance. The culmination of this module is the presentation of comprehensive results in a detailed report.
In this documentation, we have outlined the intricacies of each module, detailing the steps involved in data collection, preprocessing, feature extraction, and model development. The comprehensive approach ensures a thorough understanding of the project's methodology, culminating in the evaluation and reporting of the NLP model's performance. grounding response for a soil moisture detector. project serves as a vital solution to the challenges posed by deciphering complex medical transcriptions. By implementing a comprehensive preprocessing pipeline and leveraging advanced machine learning techniques, the model enhances patient segmentation, contributing to more efficient and customized healthcare management. The future roadmap includes continuous improvements, ensuring the adaptability of the model to evolving healthcare demands
Results
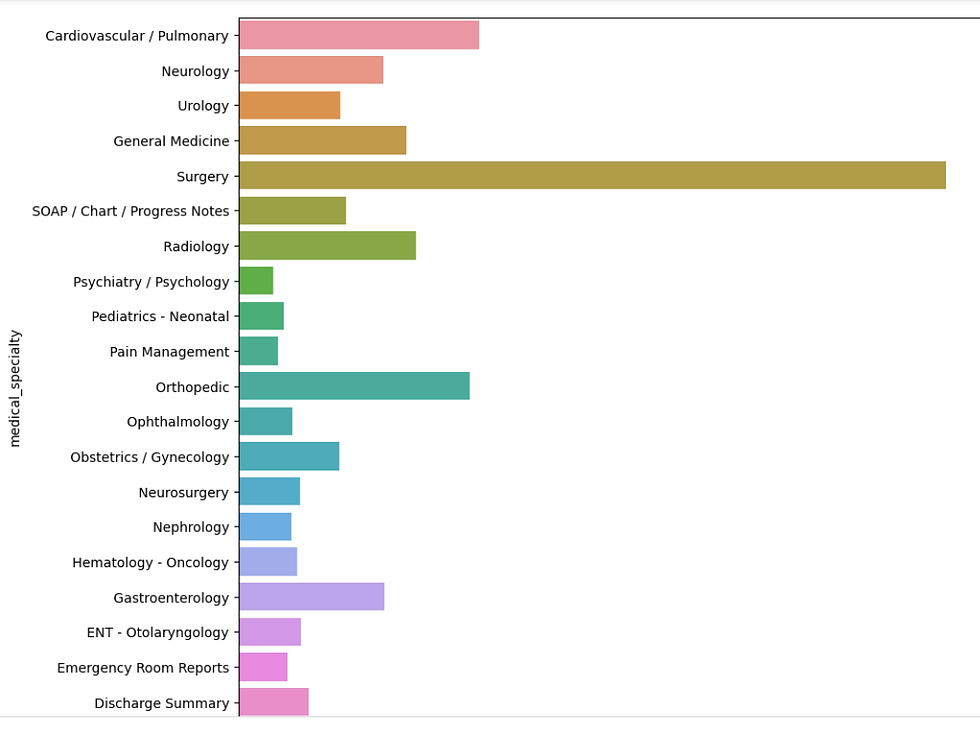
4.1The results of our implemented model reveal promising insights into the categorization of medical transcriptions. The Random Forest Classifier, trained on a diverse dataset of medical writings, achieved an average accuracy of approximately 39%. While this accuracy may appear modest, it signifies a significant step toward understanding and segmenting patients based on their transcriptions.
In the context of patient segmentation, the model demonstrates the potential to streamline healthcare processes. Efficient patient categorization into specialized medical fields becomes a reality, providing hospitals with a tool to manage and allocate resources more effectively. This has direct implications for hospital staff, facilitating improved understanding of patient conditions and optimizing the delivery of healthcare services.However, the discussion also acknowledges the limitations of the current model. The relatively modest accuracy suggests areas for improvement, and further exploration of alternative machine learning classifiers is warranted. Experimenting with different algorithms and fine-tuning parameters may enhance the model's accuracy and broaden its applicability.Moreover, the discussion touches upon the importance of continuous improvement. As the model evolves,
Customization features could be introduced to allow hospitals or clinics to define specific categories or tags tailored to their unique needs. This adaptability ensures that the model remains versatile and applicable across various healthcare settings.
In conclusion, the results and discussion highlight both the achievements and areas for refinement in our medical transcription categorization model. The project lays a foundation for future enhancements, emphasizing the significance of iterative development and customization to meet the evolving demands of healthcare institutions
4.2 Significance of the Proposed Method with its Advantages
Enhanced Patient Segmentation:
The model excels in categorizing patients into specialized medical fields based on their transcriptions. Enables healthcare institutions to efficiently manage and segment patients, improving overall patient care.
Real Medical Data Utilization:
Leveraging a Kaggle dataset of real medical writings ensures the model is trained on authentic and diverse medical transcriptions. Enhances the model's ability to handle the complexity and variability present in actual medical records.
Robust Preprocessing Pipeline:
A rigorous preprocessing pipeline, including data cleaning and lemmatization, ensures the quality and relevance of input data. Results in a refined dataset that contributes to the model's accuracy and performance.
Implementation of TF-IDF vectorization:
Transforms textual data into numerical vectors. Captures the importance of words in context, providing a robust foundation for the subsequent analysis.
Efficient Feature Space Management with PCA:
Principal Component Analysis (PCA) is employed to handle the extensive feature space generated during TF-IDF vectorization. Reduces data dimensionality, addressing computational complexity and optimizing subsequent analysis.
Random Forest Classifier for Accurate Categorization:
The utilization of the Random Forest classifier enhances the model's accuracy in categorizing patients. Provides a robust machine learning algorithm for effective medical data segmentation.
Customization for Specific Healthcare Needs:
Future enhancements include the ability to create custom categories or tags based on specific hospital or clinic.
Privacy and Ethical Considerations:
The implementation adheres to strict privacy standards and ethical guidelines in handling sensitive medical data. Robust measures are in place to anonymize patient information, ensuring compliance with privacy regulations and fostering trust among patients and healthcare providers.
Community Involvement and Open Source Contributions:
The project encourages community involvement by fostering an open-source approach. This not only contributes to the model's refinement through collaborative efforts but also promotes knowledge sharing within the healthcare analytics community, fostering continuous improvement and innovation.
In conclusion, the proposed method goes beyond technical excellence, addressing practical considerations such as scalability, interpretability, privacy, and user-friendliness. Its holistic approach, combined with a commitment to ongoing improvement and ethical standards, positions it as a valuable asset in the advancement.
V. CONCLUSION AND FUTURE ENHANCEMENTS
5.1 conclusion and future enhancements
In conclusion, this project effectively addresses the intricate challenge of deciphering and categorizing medical records and transcriptions to streamline patient management within healthcare institutions. Leveraging a Kaggle dataset of authentic medical writings, a rigorous preprocessing pipeline has been implemented, involving data cleaning, lemmatization, TF-IDF vectorization, and dimensionality reduction through PCA. The utilization of a Random Forest classifier ensures accurate patient categorization into specialized medical fields, providing a valuable tool for hospital staff to efficiently manage and allocate resources.
The advantages of this method lie in its enhanced patient segmentation, real medical data utilization, robust preprocessing, and efficient feature space management. By offering a numerical representation of medical transcriptions and optimizing the model's accuracy, this project contributes significantly to improved patient care and overall hospital management. Looking forward, there are several avenues for future enhancements to further refine and extend the capabilities of the model. These include exploring alternative machine learning classifiers, introducing customization features for specific hospital needs, integrating the model with electronic health record systems, continuously enriching the dataset, incorporating advancements in natural language processing, developing a user-friendly interface, implementing real-time patient segmentation, and collaborating with healthcare providers for valuable feedback.
In conclusion, this project establishes a solid foundation for efficient patient management in healthcare institutions, and the proposed future enhancements aim to ensure its sustained relevance and effectiveness in the dynamic landscape of medical data analysis and patient care.
Figure 3.Sample code setup
Future Enhancements
In terms of future enhancements, there are several avenues to refine and extend the capabilities of the developed model. Firstly, exploring alternative machine learning classifiers beyond the Random Forest algorithm could offer insights into whether different approaches might further enhance the accuracy of patient categorization.
Additionally, introducing customization features would allow the model to adapt to specific hospital or clinic requirements, providing a more tailored and flexible segmentation solution. Integration with electronic health record (EHR) systems represents another promising avenue. This could create a more seamless and comprehensive healthcare management solution, bridging the gap between patient categorization and broader health information.
Continuously enriching the dataset with new and diverse medical transcriptions is crucial to ensuring the model's adaptability and relevance in evolving medical. Staying abreast of advancements in natural language processing (NLP) techniques is imperative. Incorporating cutting-edge methodologies could significantly improve the model's performance, enabling it to better understand and categorize complex medical language.
Developing a user-friendly interface is essential for facilitating ease of use among healthcare professionals, ensuring the model can be seamlessly integrated into existing healthcare workflows. Exploring the feasibility of real-time patient segmentation is another avenue for improvement. Implementing capabilities for immediate categorization and response to changing healthcare demands would enhance the model's practical utility.
Lastly, fostering collaboration with healthcare providers to gather feedback on the model's performance is crucial. This ensures alignment with real-world healthcare scenarios and the evolving needs of medical professionals, contributing to the ongoing refinement and effectiveness of the developed solution.
The model encourages collaboration between medical professionals and data scientists. By fostering interdisciplinary communication, it promotes a holistic approach to healthcare management, where domain expertise combines with advanced analytics for more comprehensive patient care strategies.
Validation and Benchmarking
Rigorous validation procedures and benchmarking against existing methods in medical data analysis contribute to the credibility of the proposed method. Comparative studies showcase its superiority, building confidence in its efficacy and encouraging widespread adoption. The model's accurate patient segmentation and streamlined processes contribute to cost-efficiency and resource optimization within healthcare institutions. By allocating resources more effectively, it helps mitigate operational expenses and enhances overall financial sustainability.
VI. ACKNOWLEDGEMENT
I would like to express my sincere gratitude and appreciation to the Department of Artificial Intelligence and Machine Learning , for their invaluable support and guidance during my research project.
REFERENCES
[1] Iuliia Lenivtceva,Georgy Kopanitsa, Preprocessing of unstructured medical data: the impact of each preprocessing stage on classification ,2020”
[2] Machine learning in medicine: a practical introduction to natural language processing,2021,”https://bmcmedresmethodol.biomedcentral.com/articles/ 10.1186/s12874-021-01347-1”
[3] “Neural Natural Language Processing for unstructured data in electronic health records: A review,2022” https://www.sciencedirect.com/science/article/abs/pii/S157401372200045 4
[4] ”Segmentation and Feature Extraction in Medical Imaging: A Systematic Review,2020”
[5]“Using Natural Language Processing to Automatically. Assess feedback quality finding from 3 surgical Residencies,2021”https://pubmed.ncbi.nlm.nih.gov/33951682/
[6] ”Applications of natural language processing in ophthalmology:
present and future,2022”https://pubmed.ncbi.nlm.nih.gov/36004369/
[7] Artificial intelligence in healthcare: transforming the practice of medicine,2021”https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8285156/
[8] ““Deep Learning for Medical Image Processing: Overview, Challenges and the Future, 2019”
[9] “Using natural language processing to understand, facilitate and maintain continuity in patient experience across transitions of care, 2022”
[10] ”Healthcare A Systematic Review of Natural Language Processing in Healthcare,2016”
[11] “Sentiment Analysis in Health and Well-Being: Systematic Review ,2020”
project gallery
 |  |  |  |
|---|---|---|---|
 |  |